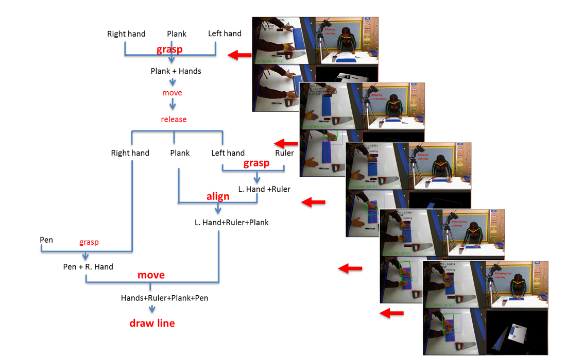
Learning for action-based scene understanding
Action plays a central role in our lives and environments, yet most Computer Vision methods
do not explicitly model action. In this chapter we outline an action-centric framework which
spans multiple time scales and levels of abstraction, producing both action and scene inter-
pretations constrained towards action consistency. At the lower level of the visual hierarchy
we detail affordances – object characteristics which afford themselves to different actions.
At mid-levels we model individual actions, and at higher levels we model activities through
leveraging knowledge and longer term temporal relations. We emphasize the use of grasp
characteristics, geometry, ontologies, and physics based constraints for generalizing to new
scenes. Such explicit representations avoid over-training on appearance characteristics. To
integrate signal based perception with symbolic knowledge we align vectorized knowledge
with visual features. We finish with a discussion on action and activity understanding, and
discuss implications for future work.
Read more here: http://users.umiacs.umd.edu/~fer/postscript/learning-actions-chapter.pdf